matej.prokop | September 23rd, 2021
This blog is a practical guide describing how we implemented canary testing to improve the quality of our cloud-based service. It presents a solution we successfully used at OneLogin for two years and points out the pros and cons of our solution.
What is canary testing
Canary testing is a technique to gradually roll out a change to your users. You start with a small subset of users and monitor its operation. When no issues are observed on this small sample, you increase the number of targeted users over time and eventually all users get the new code. Using this technique you lower the risk of deploying bad code to all users and breaking your service for all users.
Canary testing is an addition to other testing practices - unit, integration and end-to-end testing. When you discover an issue in canary testing, it means that some customers were affected. It is better than having it affect all customers; however, you should thoroughly test your code before putting it into canary testing.
Anyway, even with good test coverage, canary testing remains a valuable tool. Firstly, development and staging environments often don’t fully match production environments. Hence, canary testing can detect issues that may not have been found when testing in other environments. Secondly, there could be some “edge cases” or “unpredictable scenarios” that no-one has thought of during regular testing.
Our solution
Canary cluster
We decided to create a standalone canary cluster (orchestrated docker containers) in our production environment. It was created as a separate cluster to make sure that any misbehaving component from a canary test won’t affect services in the production cluster. (This allows us to test not only a new version of any of our services, but to test infrastructure changes as well with canary testing.)
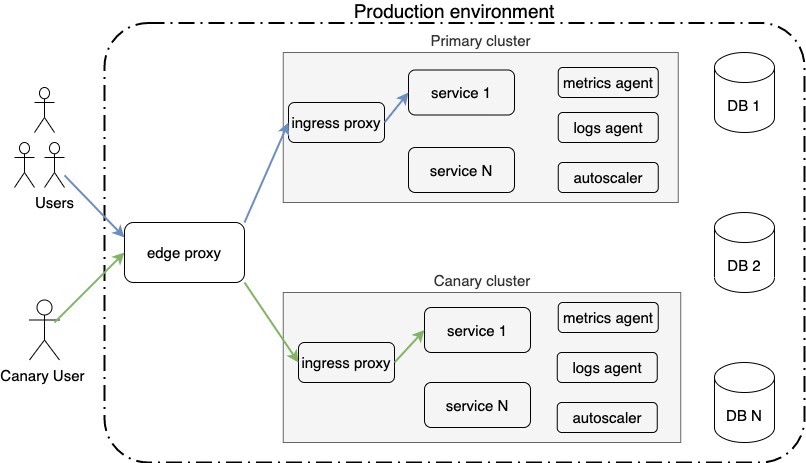
Note that the canary cluster is an exact copy of the primary cluster (ordinary handling production traffic), and there are all mandatory components/services such as an autoscaler or service agents for collecting metrics and logs. On the other hand, services in canary share databases with the primary cluster (operates with the same data).
Routing canary traffic
The next step was to update HAProxy configuration (we use HAProxy as an edge proxy for routing of our HTTP traffic) to support routing traffic to the canary cluster. For instance, to add support for canary testing of foo-service (imagine that foo-service provides HTTP REST API for our users), we have following configuration in HAProxy config:
acl foo-service path_beg /foo use_backend be_foo_service if foo-service backend be_foo_service balance roundrobin cookie foo_canary_insert indirect nocache domain .yourdomain.com server server1 primary-cluster.placeholder.net:443 ... weight 100 cookie true server server2 canary-cluster.prod.placeholder.net:443 ... weight 0 cookie false
With this configuration in place, any request for foo-service is routed into either primary or canary cluster based on the associated weight.
Note that foo-service handles all requests having “/foo” prefix in its URL and there is a dedicated HAProxy backend rule for this service in HAProxy config. The backend for foo-service has two servers registered - one for canary traffic and a second for primary traffic. By adjusting weights for those servers, we are able to control what percentage of traffic will go to the canary cluster.
For instance, when you set the weight for primary-cluster to 90 and for canary-cluster to 10, then HAProxy sends 10% of traffic for a given service into the canary cluster. Note: We have an independent configuration of canary testing for every (micro)service.
Also, with the configuration above, it remembers the decision (primary-cluster vs canary-cluster) into a cookie called “foo_canary_ Therefore, on the first request from the user to foo-service HAProxy decides based on weights where the request will be routed and stores this decision into this cookie. Later any following request for foo-service from the user will hit the same cluster (based on cookie). This mechanism ensures that ONLY a configured percentage of users go to canary and that a user won’t be randomly presented back and forth with new and old versions of the service.
Cookie suffix
Every canary test should run only for a limited period of time (either you decide to promote to production or stop the test when some issue is found). Therefore, keeping the decision in the canary cookie forever is not desired. To deal with that our canary cookie has “
- You are testing foo-service with 1% using following configuration:
cookie: "foo_canary_10"; canary weight: 1, primary weight: 99
- You found an issue during testing so you stop the test by configuring:
cookie: "foo_canary_11"; canary weight: 0, primary weight: 100
Note that the suffix in the cookie name was changed from 10 to 11. Every time the name of the cookie is changed, it forces HAProxy to make a new decision based on new weights so your change takes an immediate effect. We use a simple number as a suffix and increment it over time.
Note: If you change weights but keep the cookie name the same then the new configuration will be applied only to users that don’t have a cookie yet.
Updating HAProxy config
Now you should have a good picture of what our initial implementation of canary testing looked like. It worked and was pretty useful, but it had one major disadvantage: it required us touching HAProxy configuration (and reloading HAProxy) everytime we wanted to update canary testing. Even with HAProxy nodes being managed by puppet it was not sustainable going forward because of following reasons:
- The edge proxy is one of most critical components and “manually” messing with its configuration is just too risky.
- HAProxy configuration is an unnecessarily complex “interface” to configure canary testing.
- Puppet was propagating changes within 1 hour which was a way too slow.
Therefore, we decided to improve it!
GitOps way using Consul
To eliminate pain points mentioned above we implemented a mechanism where configuration for canary testing resides in a simple JSON file stored in a Git repository. By updating configuration in Git, changes are propagated into all HAProxy nodes within 1 minute. Here is diagram of how it works:
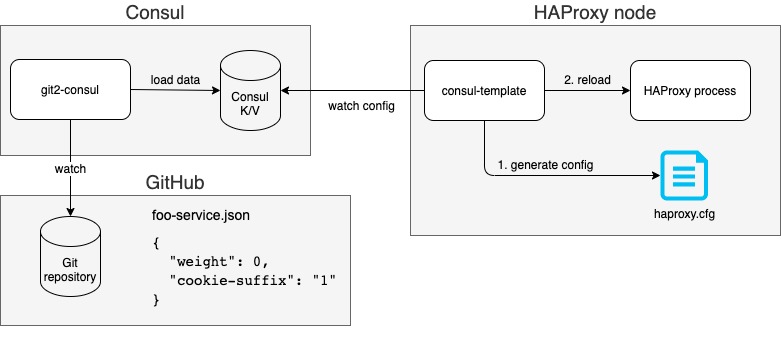
We created a Git repository that holds canary testing configuration for our services. Every service has a dedicated JSON file there with simple format: “weight” which represents percentage of traffic going to canary (number from 0 to 100) and “cookie-suffix” used as the suffix for canary cookie in HAProxy. By merging changes in configuration to the “prod” branch, the change is applied to HAProxy nodes in the production environment.
In our production environment, we operate git2consul service that mirrors Git repository(s) into Consul key-value store (described later), and it is configured to watch and mirror the “prod” branch of the repository with the canary configuration. It is possible to configure git2consul via JSON file and here is an example of such file you can start with:
{
"version": "1.0",
"repos": [
{
"name": "abc_consul_canary_data",
"include_branch_name": false,
"ignore_repo_name": true,
"ignore_file_extension": true,
"expand_keys": true,
"url": "",
"branches": ["{BRANCH_IN_YOUR_REPO}}"],
"hooks": [
{
"type": "polling",
"interval": "1"
}
]
}
]
}
Then we have a Consul cluster that is used only as a key-value store in our canary mechanism. Nice thing about Consul is that it comes with a tool called consul-template that provides an elegant way to generate a file based on content in the Consul key-value store. In our flow, it is used to update the HAProxy configuration file anytime with canary configuration changes.
Therefore, we run consul-template as a “linux” service on HAProxy nodes, where consul-template is responsible for generating the configuration file for HAProxy. Whenever canary configuration in key-value store changes then consul-template detects that, generates a new config for the HAProxy and reloads it (by reloading you tell the HAProxy process to load a new configuration from file). To make that possible we have the HAProxy configuration defined as template for consul-template - our previous example with foo-service would be transformed into a template in following way:
{{$fooWeight := keyOrDefault "haproxy/canary/foo-service/weight" "0" | parseInt}}
{{$fooSuffix := keyOrDefault "haproxy/canary/foo-service/cookie-suffix" "0" }}
backend be_foo_service
balance roundrobin
cookie foo_canary_{{$fooSuffix}} insert indirect nocache domain .yourdomain.com
server server1 primary-cluster.net ... weight cookie true
server server2 canary-cluster.net ... weight {{$fooWeight}} cookie false
Note that we have default values defined (via keyOrDefault) that are used when the Consul cluster is unavailable - in that case we turn canary testing off as fallback.
You can configure consul-template to generate an haproxy.cfg into a temporary location and then execute a custom script that validates the generated configuration (for instance using “/usr/sbin/haproxy -c -V -f path-to-config-file” command), do a backup of the current configuration, replace haproxy.cfg and then reload the HAProxy.
Conclusion
Alright folks, that’s how our canary testing works. It definitely isn’t a perfect solution, but we are quite happy with it right now. It is extremely easy for our developers to use (everybody knows how to use Git and update a simple JSON file, right?) and the quick propagation time makes a big difference for user experience and in developers’ comfort.
Reasons why it isn’t perfect are:
- Canary configuration isn’t validated (we solve this by relying on a peer review process).
- It is not easy to see canary configuration for all services (configuration is spread over multiple files) without building some custom dashboard for it.
- It is a manual process that requires people to drive it. :)
Finally, I would like to mention that it isn’t so straightforward to set up a Consul cluster and it can be a bit of an overkill when you need it only for the key-value store.
Thank you for reading. I hope you enjoyed it ;)

Matej Prokop is Principle Software Engineer at OneLogin with 10 years of professional experience who loves challenges. As co-founding member of OneLogin Platform team, he helped building a modern, highly reliable and scalable IDaaS platform.