matt.barrio | October 8th, 2021
In August of 2016, OneLogin was growing at a rapid pace by increasing revenue, hiring more staff, and offering new services. OneLogin has always innovated at lightning speed, but we were hitting a bottleneck with service configuration, monitoring setup, instance provisioning, and operational backlogs. This meant getting new services to production would take months after they were ready to ship. These challenges lead us to launching our containerization effort. I teamed up with one of our engineers, Arun, on the project. Our bosses served us up as sacrificial lambs, as we were assigned no other resources and the requirements were vague: “We need to start using Docker.” So was born our #docker Slack channel (now renamed after our internal developer tool, ike. Oddly, Slack doesn’t keep the original channel names when viewing the history).
A Sprint for Adoption
We started with the basics - we got a registry set up and began to push images to it. Arun and I decided the path of least resistance was to spin up a self-hosted registry to avoid going through a lengthy security and compliance review process for managed services, like Docker Hub or AWS’s ECR. A few days later, we had a working v1 and started creating Dockerfiles in a few core repositories.
In January 2017, we had our first commit that contained a MASSIVE docker-compose.yml file to our docker repository. This repository would later become the primary repository for all of our docker tooling. The giant compose file contained all of our service definitions in a single stack. With only a `docker-compose up` command, we had our entire environment running locally. It was a big first step, and aside from our laptops sounding like airplanes, we were happy with the results.
As April arrived, Arun and I were fielding questions from almost every team about local setups, building images, CI, networking, and so on. We were reaching a critical mass as nearly everyone in the engineering org was using some form of Docker. Arun and I continued to add Dockerfiles and Makefiles to all the service repositories and get builds set up in our TeamCity, our then CI.
In May, one of our engineering leaders, Tomas, my now boss, was working with his team to spin up a new service. He offered the service as the first to go to production in a container.

The engineering and TechOps team ultimately decided not to ship this service in a container, as we hadn’t yet settled on the orchestrator we would use in production. They proceeded with static EC2 instances behind an ELB. Once the service was ready to be shipped to production to start beta testing, we faced two months of configuration problems, operational backlogs, and resource constraints. In late July we deployed the service in our legacy EC2/ELB deployment model as opposed to Swarm.
Why did it take so long?
- The deployment model had very siloed work boundaries.
- Developers didn’t have read/write access to the configuration management or IaC repos.
- The Operations team didn’t touch the CI components and had a large backlog for compute provisioning.
- As the gatekeeper for deploy jobs, Release Management had their own backlog for creating and running release tests.
No single person or team could be the owner from start to finish. It was not one person’s fault but years of uncoordinated and fragmented decisions that led to this state. Removing all the overhead and bottlenecks of the current processes was what we intended to resolve with shipping containers to production.
The Orchestration Arms Race
As we approached August, we finally landed on which orchestrator to use. There were a few facets to this decision. Few people in the company were familiar with Docker or containers, so we needed a solution that would provide the least friction for every team involved. We wanted teams to have autonomy for their service’s life cycle, including configuration. Our Operations team was already overwhelmed with our current infrastructure, so adding a large burden to the team wasn’t going to fly. With these things in mind, we quickly eliminated a self-hosted Kubernetes cluster due to the overall complexity. We considered AWS’s ECS, but it wasn’t clear how we would map it to our development environments. In addition, we were working with another Cloud Provider at the time, so we took vendor lock-in decisions off the table. Docker Swarm ended up being our orchestrator of choice. It offered the least amount of overhead to get started, and even with the significant gaps in functionality compared to other orchestrators, we felt we could easily work through those . The arms race between the different orchestrators meant development was happening rapidly across them all. And we felt Swarm had good traction and following within the developer community at the time.
Concurrently, Tomas’s team was working on another service, but this time wanted it only running in Swarm. Other teams had large backlogs for shipping their new services, and Tomas knew going that route again would be detrimental. So we began the charge of containers in production!
One of the many challenges we faced was how we were going to deploy through all the different stages and still maintain our goal of a consistent interface across environments. No tool perfectly fit our use case so we decided to build our own. The first iteration was called `ik` (later changed to `ike`). The CLI abstracted the configuration and docker commands so everyone in the organization would use the same commands across every environment.
After multiple iterations in staging and working out the kinks in the cluster deployments, we finally shipped containers to production. Things were NOT perfect, and we still had to work out autoscaling, resource constraints, and configuration templating, but it represented a major milestone in our containerization journey.
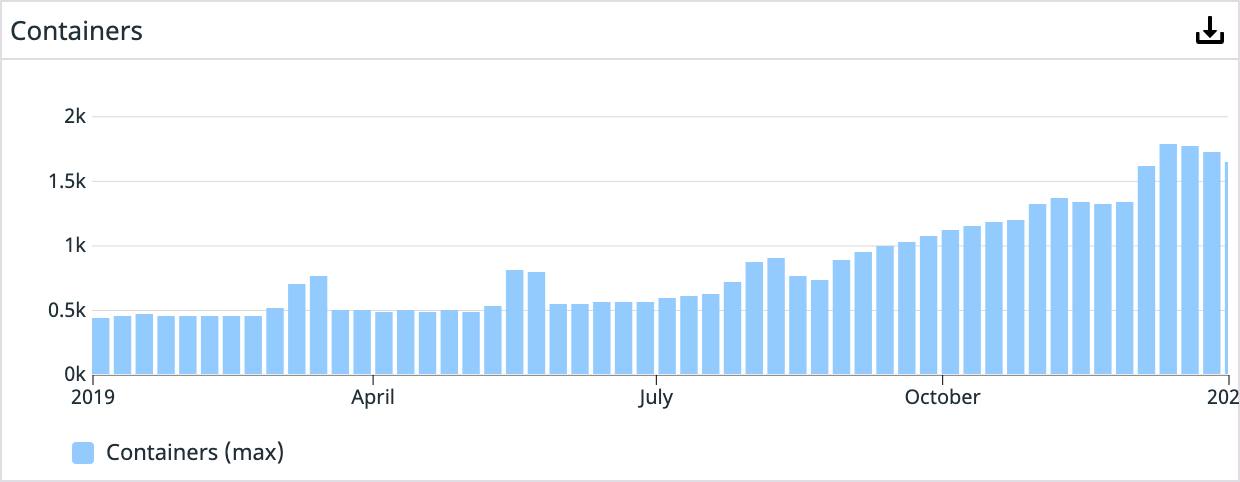
Over the next two years, dozens of engineers would help build out our containerization story. The teams developed configuration tooling, autoscaling of underlying compute resources, a custom Swarm service auto scaling tool, resource planning dashboards, cluster management tooling, the list goes on. Our Platform organization was moving at full speed to remove obstacles for our service teams. By October 30th, 2019, we had over 1,300 containers running in production.
As the end of 2019 arrived, we heard what we anticipated was coming: Docker was acquired by Mirantis, and Swarm’s EOL announcement:
“The primary orchestrator going forward is Kubernetes. Mirantis is committed to providing an excellent experience to all Docker Enterprise platform customers and currently expects to support Swarm for at least two years, depending on customer input into the roadmap. Mirantis is also evaluating options for making the transition to Kubernetes easier for Swarm users.”
Since then, Mirantis backed away from the Swarm deprecation comment, but we decided it was time to jump ship. Many of our original requirements for Swarm no longer applied. The Platform team set a 2020 goal to operate, with no significant manual intervention, at 10x our scale. We didn’t think Swarm would help us achieve that, especially as development on their open-source software slowed. Mirantis’s announcement presented the perfect opportunity to re-evaluate our orchestrator moving forward.
The next phase came with the usual challenges that occur during significant architectural changes—business requirements, operational overhead, tooling upgrades or changes, resourcing, training, etc. But in March of 2020, evaluation kicked off in the search for a new orchestration platform.
We selected AWS’s EKS, and Flux was chosen for the GitOps automation operator. The Platform team notified the engineering teams that all Swarm clusters would be decommissioned.
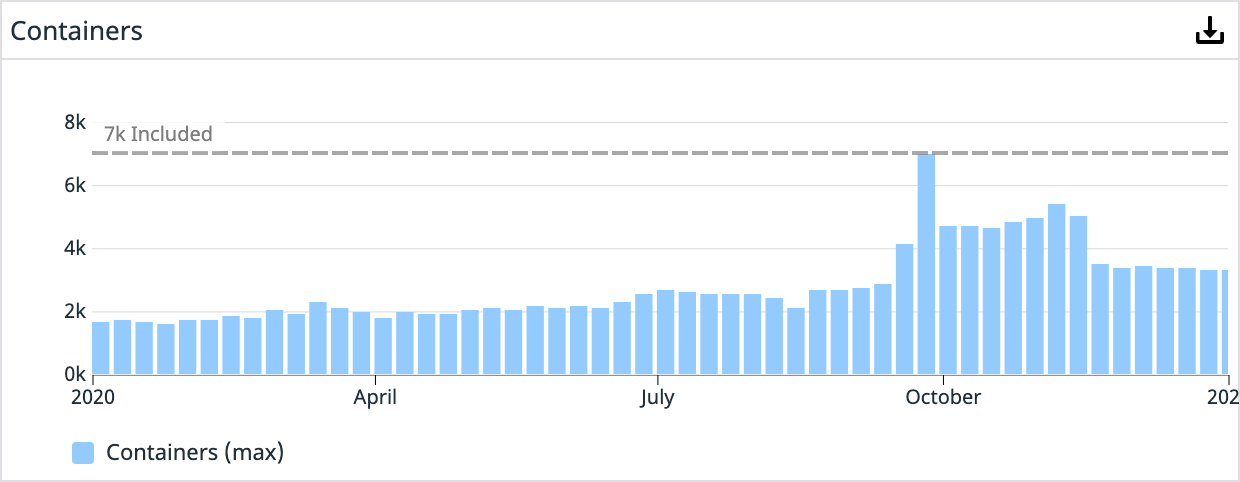
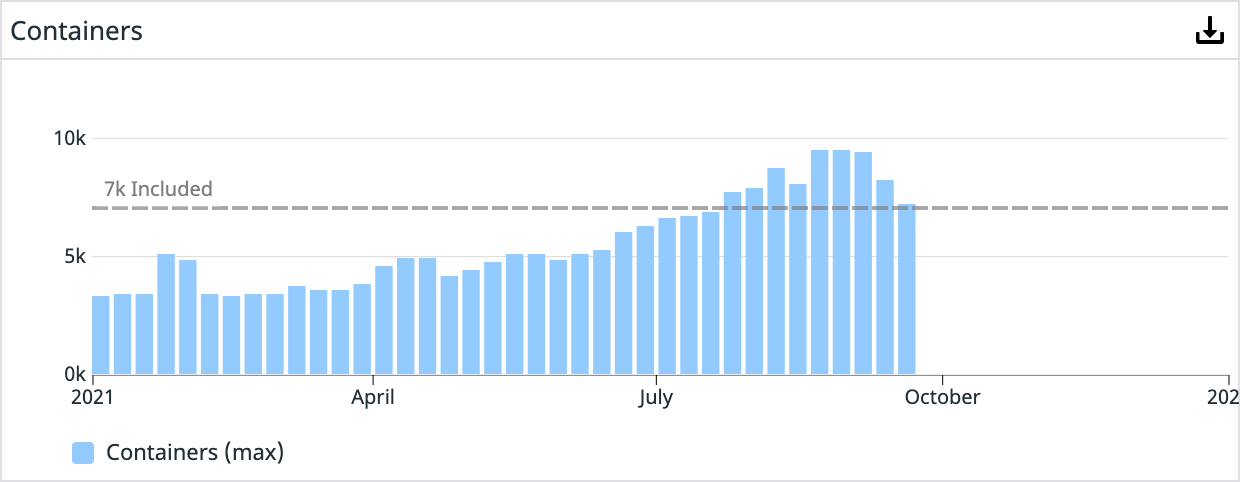
Now, we are just completing our migration to run all our production workloads in EKS. So far, things have been going smoothly, and our teams are enjoying a more self-sufficient operating mode. There is a significant learning curve, but moving the operational overhead to a managed service like EKS frees up more time for driving other critical platform initiatives. Today, we’re running more than 7,000 containers in our production clusters, and that number grows by the day.
Year-over-year graphs:

Year 1 (We didn’t start using Datadog until we were a few months into shipping containers in production. This graph doesn’t reflect the full history.)
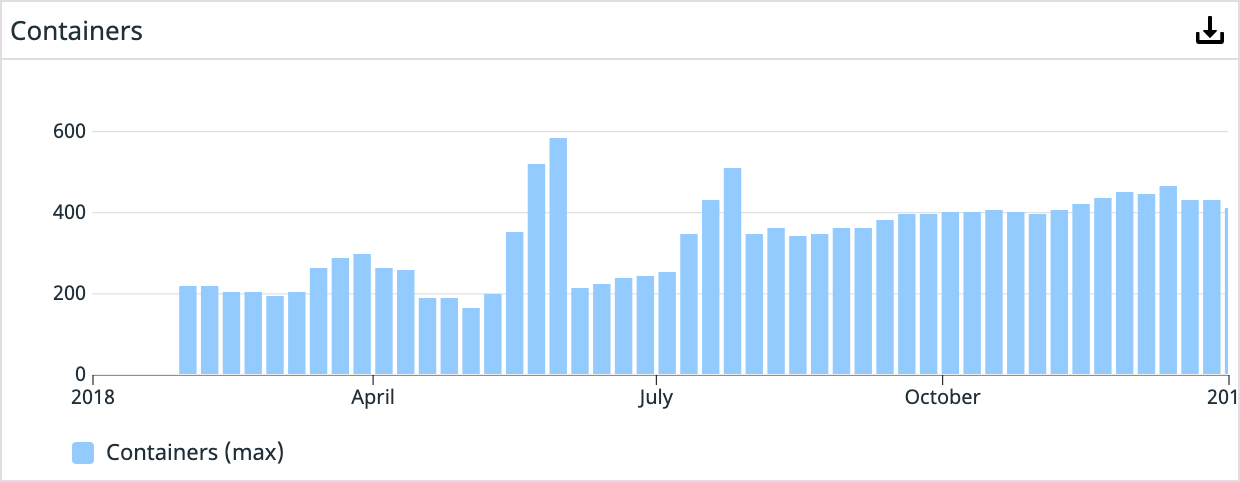
Year 2
Year 3
Year 4
There is a never-ending evolution in technology and every organization must keep up to survive. As Stefan Zier from SumoLogic puts it “systems are in a constant state of migration.” Our journey with containers started four years ago and is still evolving due to changes in both needs and requirements for the business and the platform. Having the foresight on when to start the next phase of evolution requires careful evaluation and constant reflection.
If you’d like to be a part of OneLogin’s next phase of evolution, check out our open roles!

Matt Barrio is a Director of Engineering @ OneLogin. He leads the Site Reliability team, covering OneLogin’s cloud platform while overseeing the entire Engineering organization’s reliability objectives. He is passionate about helping people grow and building things at scale, from processes to systems.