dominick.caponi | February 17th, 2021
Machine learning and artificial intelligence (A.I.) are rapidly finding new and interesting ways of changing the world. From A.I. powered toothbrushes to content recommendation engines, A.I. is making waves through our lives. Recently, A.I. has proven to be a powerful ally in cybersecurity by busting fraudsters, booting unauthorized guests, and locking down compromised systems. At OneLogin, we use the same A.I. principles that protect the biggest names in tech. Our Vigilance AI™ platform works tirelessly to detect and flag suspicious activity in your account and adds an additional layer of protection to your logins in real time if suspicious activity is detected. Here’s an insider look at how we do it.
There’s Nothing Naïve About Bayes’ Theorem Here
Bayes’ Theorem is considered one of the most important theorems in statistics. You may have seen this formula in a textbook, or a Wikipedia article, or tattooed on a stats geek before. This is the underpinning of how OneLogin analyzes user behavior to determine the risk with each login event.
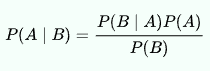
For anyone not into statistics, this is how the formula reads:
A = The event is fraudulent
B = The event we were given
P( A | B ) probability that the login is fraudulent given that it looks like the event given
P( B | A ) is the probability a bad actor sending this event
P( A ) is the probability of an event being fraudulent
P( B ) is the probability of being given an event that looks like this
Before we describe the formula, there are a few things we should get out of the way. First, the data we analyze is known as a “login event.” A login event has various features such as time of day, city location, computer model, web browser. A table of these events might look like this if you log into work every morning at 10AM.
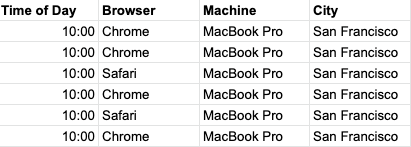
As you can see, the more times you log into work from your work MacBook in San Francisco, the more the system trusts these events. If you continue to follow the pattern you’ve set up for yourself, the probability of a login being fraud looks like this. P(B) the probability that we’d get an event like this is high, which drives the overall risk factor down, considering that the probability of an event event like this is fraud P(B|A) is low as well as the fact that most logins are not fraudulent so P(A) is low normally.
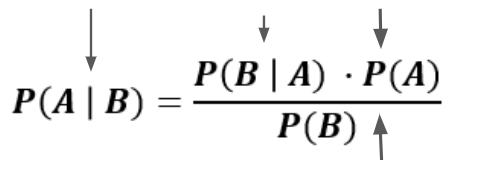
Let’s look at a suspicious event that comes in using the formula.
Example: Business Trip or Hacks?
Say we get an event that looks like this:

Given the historical data above, we conclude that it’s pretty rare that we’d see an event that looks like this. It could be from you on a business trip in Seattle and working from a loaner machine, or it could be from a bad actor in Seattle using a Windows machine. So what happens? Let’s get a risk score using the formula.
We’ll use arrow analysis for this example to illustrate what happens.
P(B) the probability we see an event like this is really low based on the fact that so many of our events are Chrome on MacBooks in San Francisco. We’ll say this is a high impact value since we have a LOT of Chrome on MacBook prior logins.
P(A) the probability someone is hacking your account is typically low since most people aren’t committing fraud. We’ll also say this is pretty high impact.
P(B|A) the probability that events like this are fraud is slightly higher given that we either don’t see it or we typically reject events like this that are assumed to be some small positive value. This is a median to low impact value.
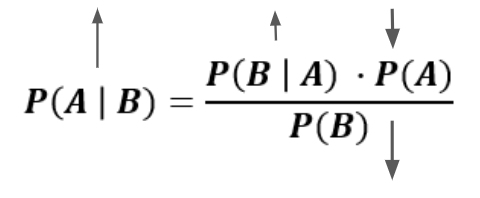
When an event has a 70% chance or higher of being evidence of account compromise, you can configure your OneLogin tenant to issue a request for a second factor of authentication. So in this case, OneLogin will send the user who just logged in through Edge on the Lenovo device a text or a prompt via OneLogin Protect on their phone. A successful second factor auth will result in the event being saved and used for later analysis.
If you move to Seattle permanently, and continue to use Edge on the Lenovo, we’ll see P(B) increase and overall P(B|A) will decrease over time, bringing the risk score down. Eventually, you won’t be pestered for additional factors as the system learns your behavior.
Bringing it Together
We just saw how we use a fundamental theorem from statistics in our machine learning application with a real life example. This powerful idea is the same concept behind the A.I.s that detect fraudulent transactions at retailers and banks because it is so effective at analyzing skewed data. We’re also able to accomplish this superior level of protection without analyzing personally identifying information such as email or physical address, phone number, or even your name. In fact, the less personal information the algorithm knows, the better job it does.
What makes the Bayes’ Theorem so great for the malicious activity scenario, is that it takes into account the fact that most login events are not fraudulent. Think about it, if you have a bag of 1 red and 99 blue marbles (fraud, not fraud marbles) and you guessed randomly that you’d get a blue marble, you’d be right 99% of the time. That’s great for guessing games, but not so great when you want an accurate, non-obtrusive fraud detection system, and Bayes’ Theorem takes that into account.
So there you have it, a sneak peak and simple example of how OneLogin uses A.I. and Big Data to keep you and your company safe in the ever-evolving cybersecurity landscape.

Dominick is a Senior Software Engineer building a community around OneLogin’s open-source projects, heading up API development, and building cutting-edge developer tools that empower developers to make authentication and access managment easy.